n8nワークフローテンプレート「Content Farming」のステップ2では、収集した記事の中から関連性の高いものを絞り込み、それをもとにブログタイトルを生成します。このステップは、質の高いブログ記事を効率的に作成するための重要なプロセスです。
ステップ2の全体構成
ステップ2は大きく分けて以下の5つのブロックで構成されています:
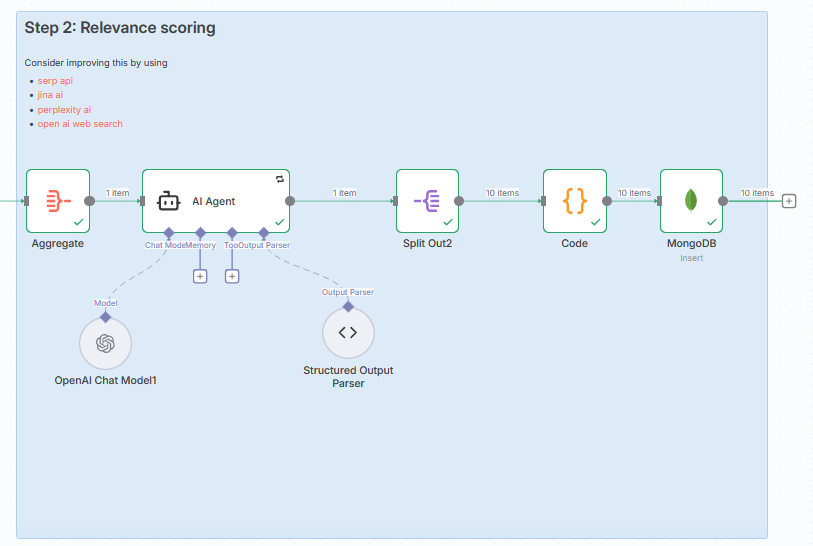
- Aggregateノード – 記事データをまとめる
- AI Agentノード – AIでタイトル案を生成
- Split Out2ノード – 生成されたタイトルを分割
- Codeノード – completed_stepフラグを追加
- MongoDBノード – データベースに保存
ブロック1:Aggregateノード
最初のAggregateノードは、ステップ1で収集・フィルタリングされた複数の記事データを1つのアイテムに統合します。n8n+1
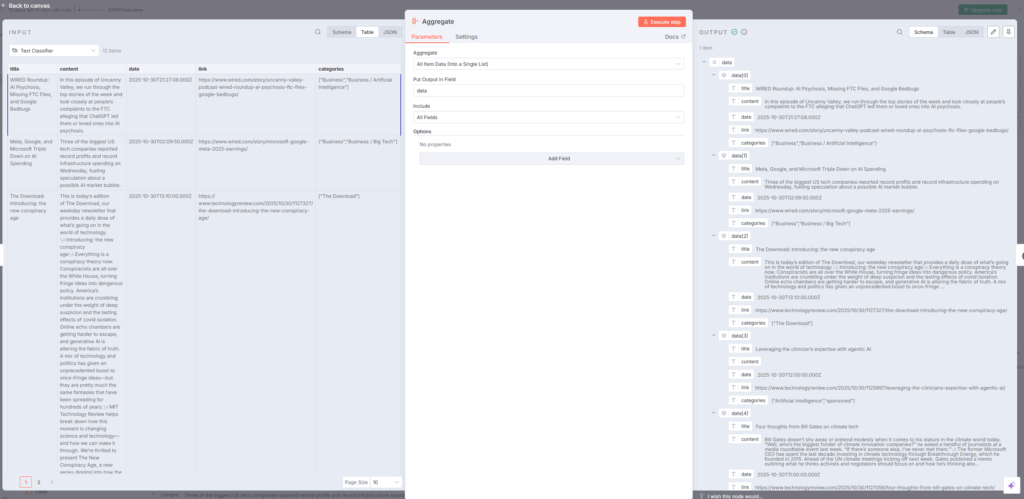
役割と設定
このノードは「aggregateAllItemData」モードで動作し、24時間以内に公開されたAI関連記事すべてを1つのJSONオブジェクトにまとめます。出力フィールド名は「data」に設定され、次のAI Agentノードが全記事情報にアクセスできるようにします。ryanandmattdatascience
なぜAggregateが必要か
AI Agentに複数のトレンド記事を一度に分析させ、それらを横断的に理解した上でブログタイトルを生成させるためです。個別の記事ごとに処理するよりも、トレンド全体を把握した上での提案が可能になります。c-sharpcorner+1
ブロック2:AI Agentノード(AI Agent)
次に、OpenAI GPT-4o-miniモデルを使用したAI Agentノードが登場します。n8n+1

プロンプトの内容
このノードには以下のようなプロンプトが設定されています:
Here are 24 trending AI-related articles published today:
{{ JSON.stringify($json.data) }}
From this, generate:
1. 10 unique long-tail blog title ideas based on these trends
2. For each title, suggest:
- Main keyword
- Related keywords
- Suggested angle or tone (e.g. educational, provocative, analytical)
3. Ensure each title is SEO-friendly, non-generic, and future-resilient
System Message
システムメッセージには「You are a content strategist for an AI-focused blog」が設定され、AIにコンテンツ戦略家としての役割を与えています。n8n
重要な設定:Structured Output Parser
このAI Agentノードには「Structured Output Parser」が接続されています。これにより、AIの出力を決まった形式で取得できます。note+1
JSON Schemaの例:
json[
{
"title": "Why Code Review AI Like CriticGPT Might Replace Juniors",
"main_keyword": "AI code review",
"related_keywords": ["CriticGPT", "OpenAI", "developer tools", "LLM code agent"],
"tone": "analytical",
"link_articles": ["https://...", "https://..."],
"date": "2025-06-16"
}
]
この構造化により、後続のノードでタイトル、キーワード、トーンなどを正確に抽出できます。n8n+1
ブロック3:OpenAI Chat Model1ノード
AI Agentノードの下部に接続されているこのノードは、GPT-4o-miniモデルの設定を提供します。
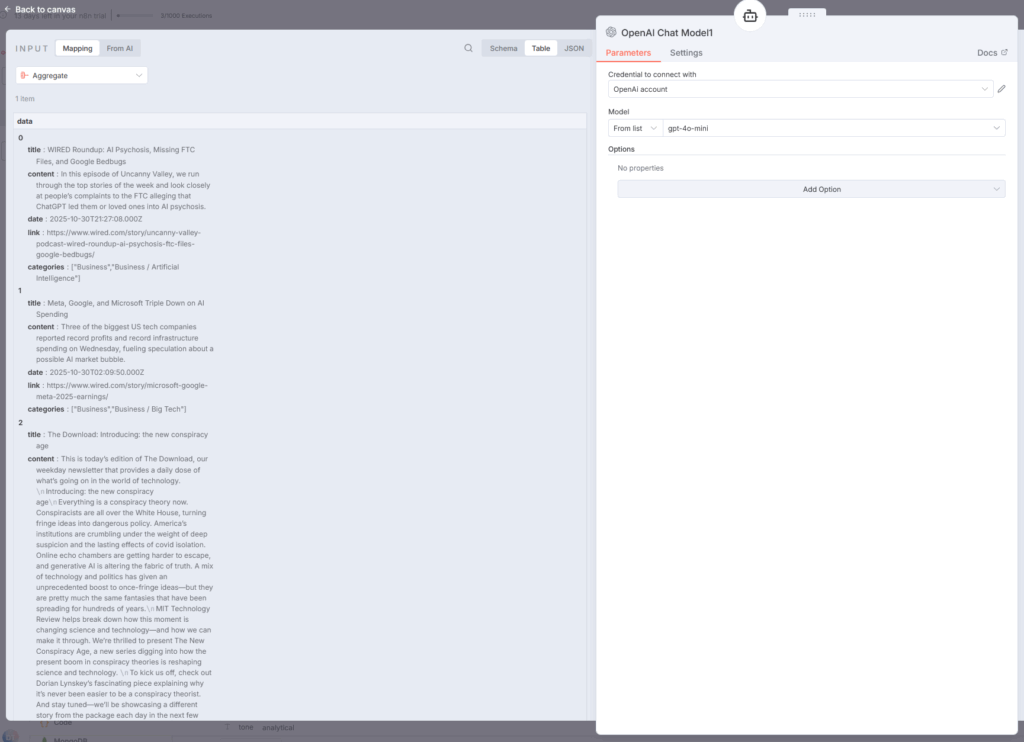
モデル設定
- モデル:gpt-4o-mini(コスト効率が高く、1日10記事で約6ドル/月)
- 認証:OpenAI APIキー
このノードをAI Agentに接続することで、言語モデルの機能を利用できます。n8n+1
ブロック4:Structured Output Parserノード
前述の通り、このノードはAIの出力を構造化します。note+1

JSON Schema設定
スキーマタイプは「Generate from JSON Example」モードで、サンプルJSONから自動的にスキーマを生成します。各フィールド(title、main_keyword、related_keywords、tone、link_articles、date)が必須項目として扱われます。n8n
なぜ構造化が重要か
n8nのような自動化ツールでは、人の手を介さずに処理を進めるため、AIの出力形式が明確でないと後続の処理ができません。Structured Output Parserを使うことで、「これがタイトル」「これがキーワード」と明確に指定できます。note
ブロック5:Split Out2ノード
Structured Output Parserから出力された配列(10個のタイトル案)を個別のアイテムに分割します。n8n
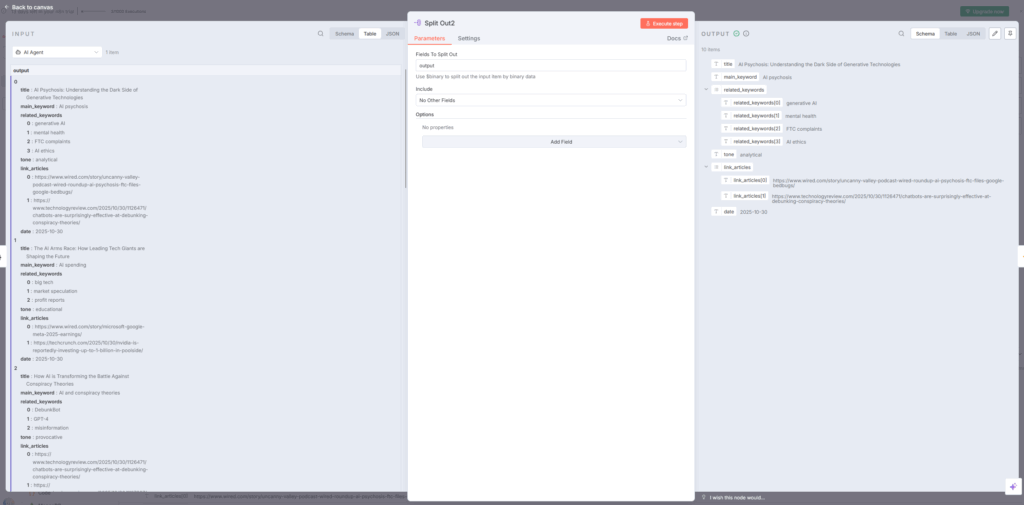
設定内容
- Field to Split Out:「output」
- Include:「allOtherFields」(他のフィールドも含める)
動作の仕組み
AI Agentから返ってくる10個のタイトル案は1つの配列として格納されています。Split Out2ノードはこの配列を10個の独立したアイテムに分割し、それぞれをMongoDBに保存できるようにします。youtube+1n8n
例えば、以下のような配列:
json[
{"title": "タイトル1", "main_keyword": "キーワード1"},
{"title": "タイトル2", "main_keyword": "キーワード2"}
]
が、Split Out2を通過すると:
アイテム1: {"title": "タイトル1", "main_keyword": "キーワード1"}
アイテム2: {"title": "タイトル2", "main_keyword": "キーワード2"}
と2つの独立したアイテムになります。
ブロック6:Codeノード
Split Out2から出力された各アイテムに「completed_step: 2」フィールドを追加します。

JavaScriptコード
javascriptreturn {
...$input.item.json,
completed_step: 2
}
このコードは、現在のアイテムのすべてのフィールドを保持しつつ、completed_stepという進捗管理用のフィールドを追加します。
進捗管理の重要性
completed_stepフィールドにより、各記事がワークフローのどの段階にあるかを追跡できます。エラーが発生した場合、どのステップで止まっているかを確認して対処できます。
ブロック7:MongoDBノード
最後に、生成されたタイトル案をMongoDBデータベースに保存します。n8n+1
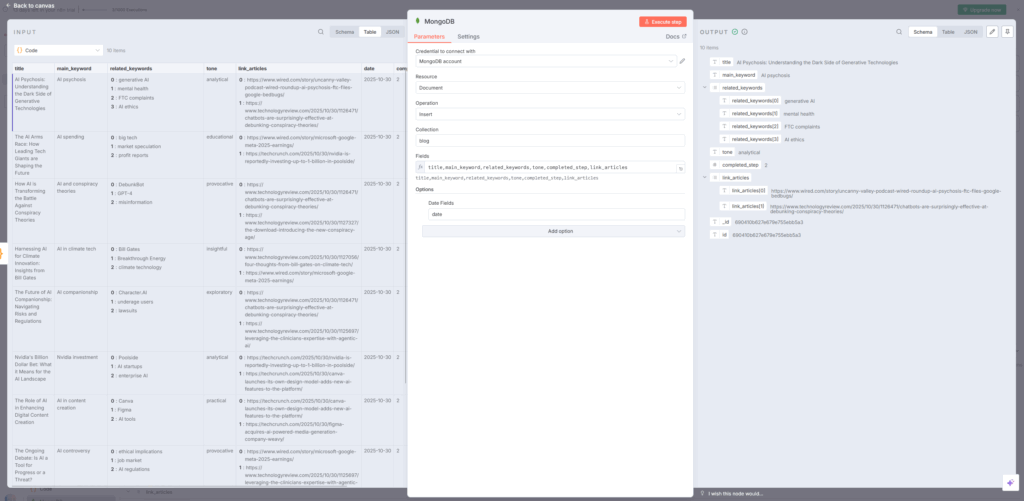
操作設定
- Operation:Insert
- Collection:blog
- Fields:title, main_keyword, related_keywords, tone, completed_step, link_articles
- Date Fields:date(日付フィールドとして指定)
フィールド指定の注意点
MongoDBノードのFieldsパラメータには、カンマ区切りのフィールド名を指定します。JSONフォーマットではなく、シンプルなフィールド名のリストです。reddit+1
例:
title,main_keyword,related_keywords,tone,completed_step,link_articles
接続文字列の設定
MongoDB Atlasとの接続には、接続文字列を使用します:
mongodb+srv://<username>:<password>@cluster0.xxxxx.mongodb.net/<dbname>
<password>と<dbname>を実際の値に置き換える必要があります。
ステップ2のデータフロー
データの流れを整理すると以下のようになります:
- 複数の記事 → Aggregate → 1つのデータ集合
- データ集合 → AI Agent → 10個のタイトル案(配列)
- タイトル案配列 → Split Out2 → 10個の個別アイテム
- 各アイテム → Code → completed_stepフィールド追加
- 各アイテム → MongoDB → データベースに保存
つまずきやすいポイントと対処法
Structured Output Parserのスキーマエラー
JSON Schemaが正しく設定されていないと、AIの出力を構造化できません。サンプルJSONは正確なフィールド名と型を含める必要があります。n8n+1
**Split OutノードでのエラーHere’s the continuation:
Split OutノードでのエラーError: this.getNodeParameter(…).split is not a functionn8n+1
このエラーは、Split Outノードに指定したフィールドが配列ではなく文字列や他の型である場合に発生します。フィールド名が正しいか、またそのフィールドが実際に配列を含んでいるかを確認してください。n8n
MongoDBのInsertエラーgithub+1
Fieldsパラメータに{{$json}}のような式を使用すると「fields.split is not a function」エラーが発生します。MongoDBノードは、カンマ区切りのフィールド名リストを期待しており、JSONオブジェクト全体を渡すことはできません。n8n+1
正しい指定方法:
title,main_keyword,related_keywords,tone,link_articles,date,completed_step誤った指定方法:
{{$json}}AI Agentの出力が不安定reddit+1
Agentノードで直接Structured Output Parserを使うと、出力が不安定になる場合があります。より安定した結果を得るには、Agentからの出力を一度受け取り、別のLLM Chainノードでパースする方法が推奨されます。n8n
まとめ
ステップ2の主なポイントは以下の通りです:
- Aggregateノードで複数記事を統合し、AIに全体像を理解させるryanandmattdatascience+1
- AI Agent + Structured Output ParserでSEO最適化されたタイトル案を構造化された形式で生成n8n+2
- Split Outノードで配列を個別アイテムに分割し、後続処理を可能にするn8n
- Codeノードで進捗管理フィールドを追加
- MongoDBノードでタイトル案をデータベースに保存し、次のステップに備えるn8n+1
このステップにより、トレンド記事から自動的にSEO最適化されたブログタイトル候補が生成され、データベースに記録されます。次のステップ3以降では、これらのタイトルを評価・選択し、実際の記事を執筆していきます。
ステップ2の理解が深まれば、n8nでのAI活用とデータ処理の基本的なパターンが身につき、他のワークフローにも応用できるようになります。n8n+1