以前紹介したn8nの自動ブログ生成ワークフロー「Content Farming」について、今回はステップ3「記事のリサーチと要約」に焦点を当てて詳しく解説します。このステップは収集したニュース記事から有益な情報を抽出し、ブログ記事の素材を準備する重要な工程です。各ノードの役割とデータの流れを、スクリーンショットとともに丁寧に説明していきます。
ステップ3の概要と役割
ステップ3は、ステップ2でAI関連と判定された記事のURLから実際のコンテンツを取得し、AIエージェントが重要な情報を抽出・要約するパートです。このステップで処理されたデータが、後続のタイトル生成や本文執筆の基礎となります。
全体の流れは以下のようになっています。

- Split Out1ノード:各記事のリンクを個別に分割
- Loop Over Itemsノード:記事を一つずつ順番に処理
- Code10ノード:記事URLから記事IDを抽出
- HTTP Requestノード:記事の全文HTMLを取得
- HTMLノード:HTMLタグを除去してテキスト化
- Transform news to MDノード:HTMLをMarkdown形式に変換
- AI Agent1ノード:重要情報を抽出・要約
- Structured Output Parser1ノード:出力形式を構造化
- Code1ノード:データを整形
- Aggregate1ノード:全記事のデータを統合
- MongoDB2ノード:データベースに保存
それでは、各ノードを詳しく見ていきましょう。
1. Split Out1ノード – 記事リンクの分割
最初のSplit Out1ノードは、前のステップから受け取った複数の記事データを個別のアイテムに分割します。このノードでは「link_articles」フィールドを指定し、各記事のURLを独立したデータとして扱えるようにします。
Split Outノードは配列やリストを個別のアイテムに分解する際に使用する基本的なノードで、後続の処理で各記事を一つずつ扱うために不可欠です。

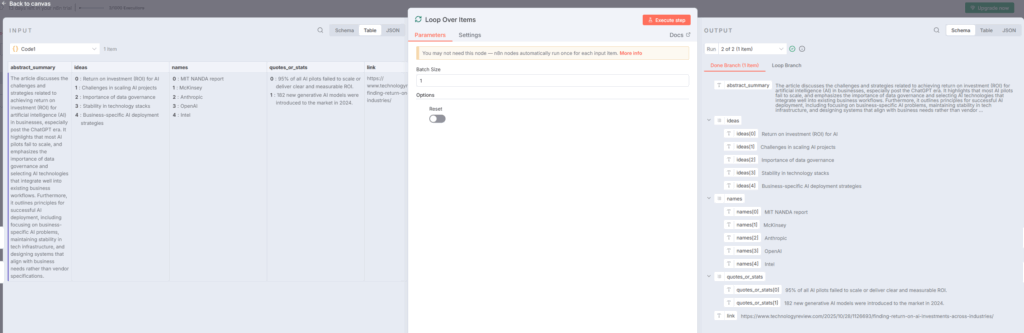
2. Loop Over Itemsノード – 順次処理の制御
Loop Over Itemsノードは、分割された記事を一つずつ順番に処理するための制御ノードです。このノードにより、複数の記事が同時に処理されるのではなく、一つの記事の処理が完了してから次の記事に進むという流れが作られます。
このノードは特にAPIリクエストのレート制限を回避したい場合や、処理の順序を厳密に管理したい場合に有効です。バッチサイズを設定することで、何件ずつ処理するかを制御できます。
3. Code10ノード – 記事IDの抽出
Code10ノードでは、JavaScriptを使って記事URLからMongoDBで使用する一意のIDを生成します。このノードは「Run Once for All Items」モードで動作し、シンプルなコードでデータ処理を行います。
実際のコード内容は画像から確認できますが、基本的には入力データから必要な情報を取り出して、次のノードで使いやすい形式に整形する役割を果たしています。

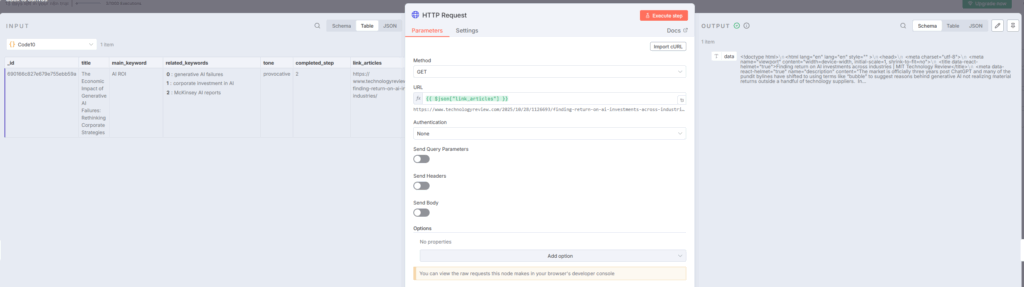
4. HTTP Requestノード – 記事全文の取得
HTTP Requestノードは、記事のURLにアクセスして完全なHTMLコンテンツを取得します。このノードでは、メソッドをGETに設定し、URLフィールドには前のノードから渡された記事リンクを指定します。
設定画面では、認証方法を「None」に、クエリパラメータやヘッダーの送信も不要な場合が多いですが、必要に応じてUser-Agentヘッダーなどを追加することも可能です。
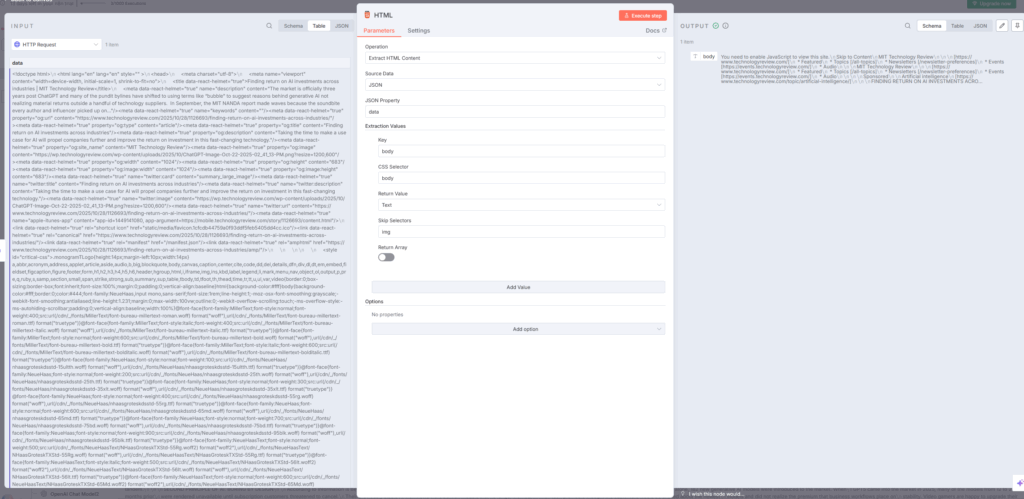
5. HTMLノード – テキスト抽出
HTMLノードは、HTTP Requestノードで取得したHTMLからテキスト部分のみを抽出します。操作を「Extract HTML Content」に設定し、ソースデータを指定することで、HTMLタグを除去した純粋なテキストコンテンツを取得できます。
このノードでは、CSSセレクターを使って特定の要素だけを抽出することも可能ですが、記事全体を取得する場合は「body」セレクターを使用するのが一般的です。
6. Transform news to MDノード – Markdown変換
Transform news to MDノードは、Code nodeを使用してHTMLコンテンツをMarkdown形式に変換します。Markdown形式にすることで、後続のAI処理がより効率的になり、テキストの構造を保ちながらデータサイズを削減できます。
このノードでは、正規表現を使ってHTMLタグを置き換えたり、不要な空白を削除したりする処理が行われています。

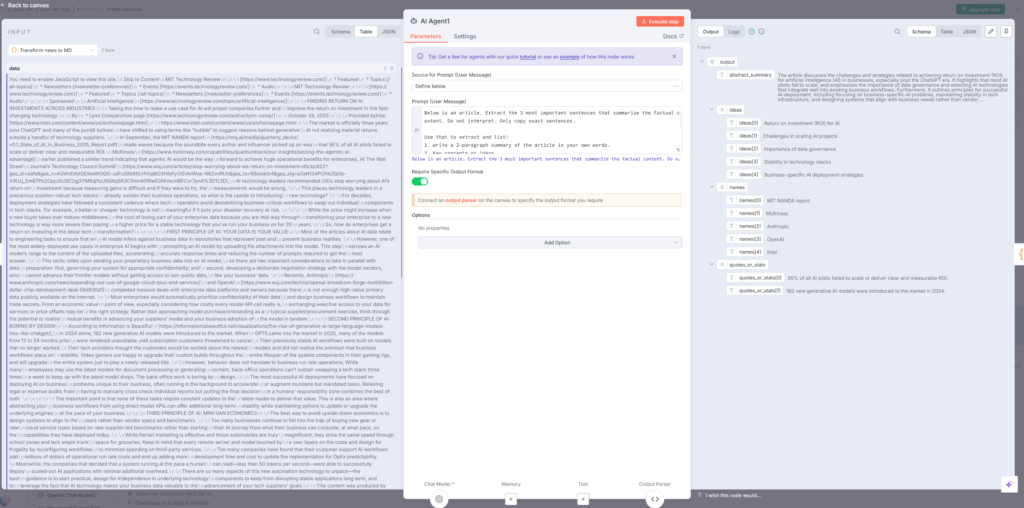
7. AI Agent1ノード – 情報抽出の中核
AI Agent1ノードは、ステップ3の最も重要な部分です。このノードでは、OpenAI Chat Modelを使用して記事から以下の情報を抽出します。
- abstract_summary:記事の要約(150語程度)
- ideas:主要なアイデアや論点のリスト
- names:企業名、モデル名、研究者名などの固有名詞
- quotes_or_stats:引用や統計データ
プロンプトには、「記事から最も重要な3文を抽出せよ」「文脈を保ちながら要約せよ」「企業名やモデル名をリストアップせよ」といった具体的な指示が含まれています。
このノードでは、システムメッセージで役割を定義し、プロンプトで具体的なタスクを指示する構造になっています。
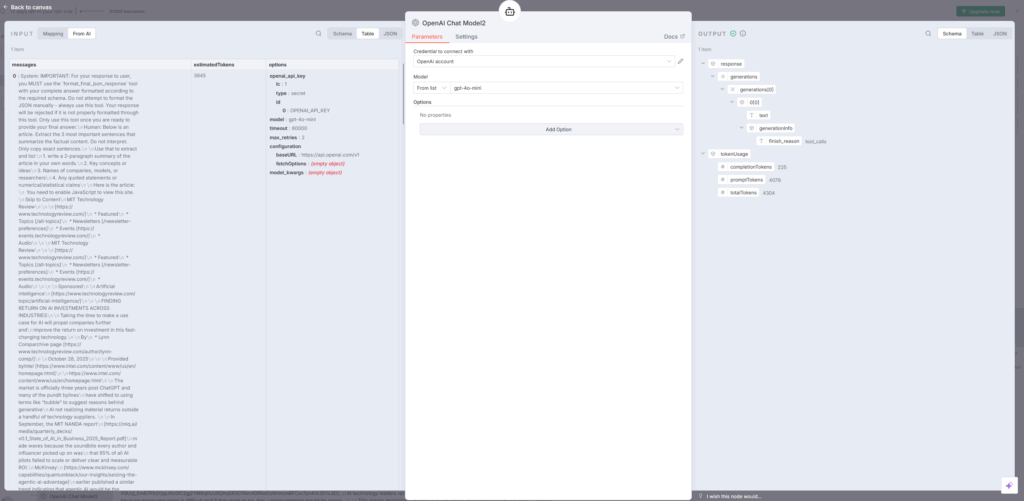
8. Structured Output Parser1ノード – 出力形式の制御
Structured Output Parser1ノードは、AI Agentの出力を一定の形式に整えるために使用されます。このノードをAI Agentに接続することで、JSONスキーマに基づいた構造化されたデータを確実に取得できます。
設定画面では、「Generate from JSON Example」または「Define using JSON Schema」のいずれかを選択し、期待する出力形式を定義します。これにより、abstract_summary、ideas、names、quotes_or_statsといったフィールドが明確に分離された形で出力されます。
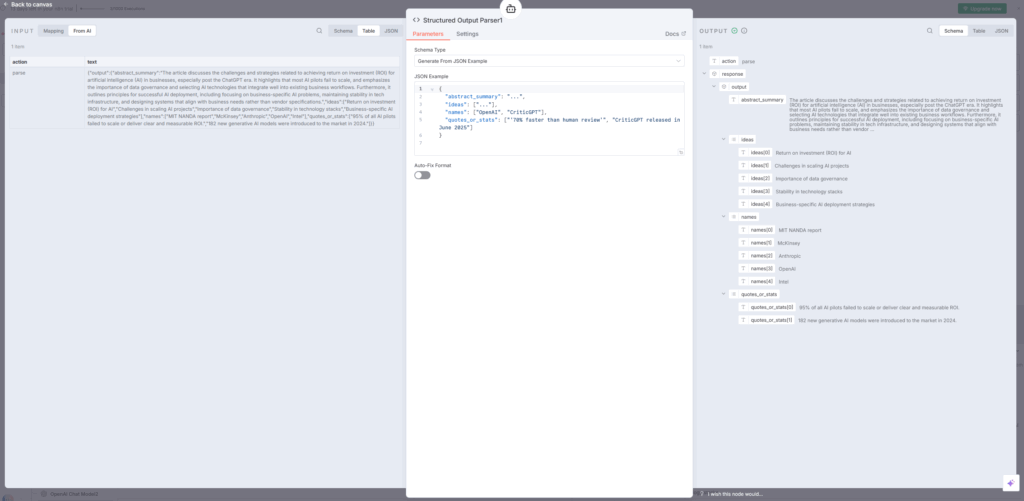
9. Code1ノード – データ整形
Code1ノードでは、AI Agentから返されたデータを次のステップで使いやすい形式に整形します。このノードでは、元記事のURLや抽出した情報をまとめて一つのオブジェクトとして返す処理が行われています。
具体的には、article.linkフィールドにURLを格納し、抽出された各情報を適切なフィールドに配置する処理が実装されています。
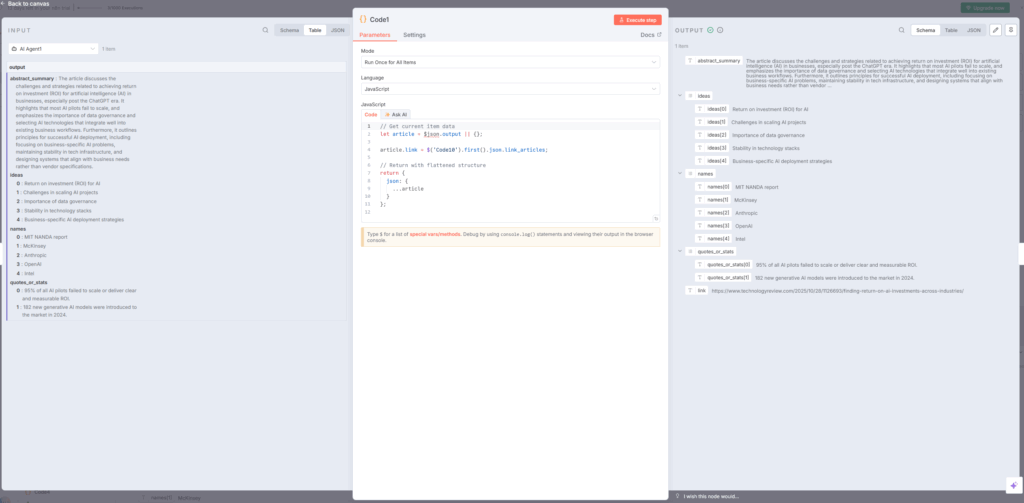
10. Aggregate1ノード – データの統合
Aggregate1ノードは、Loop Over Itemsで一つずつ処理された記事のデータを全て集めて一つのアイテムにまとめます。このノードでは、「All Item Data Into a Single List」モードを選択し、「Put Output in Field」に「articles」を指定します。
これにより、複数の記事から抽出された情報が、一つの配列として次のステップに渡されます。
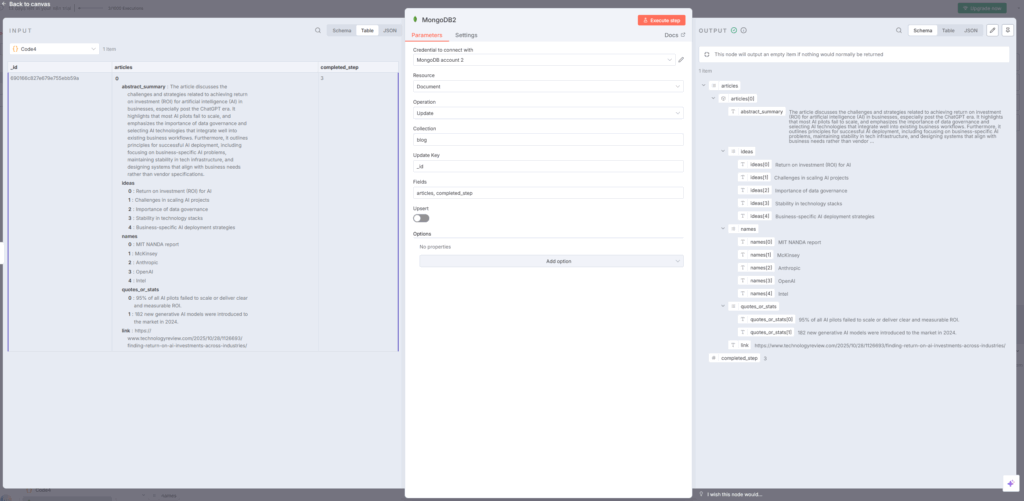
11. MongoDB2ノード – データベースへの保存
最後のMongoDB2ノードでは、統合されたデータをMongoDBに保存します。操作を「Update」に設定し、コレクション名を「blog」、Update Keyを「_id」に指定することで、既存のドキュメントを更新する形でデータが保存されます。
保存されるフィールドには、articles配列とcompleted_step(進行状況を示すフラグ)が含まれます。これにより、ワークフローのどの段階まで処理が完了したかを追跡できます。
ステップ3全体のデータフロー
ステップ3の処理フローをまとめると以下のようになります。
- 複数の記事URLを受け取る
- 各URLを個別に分割
- 一つずつ順番に処理を開始
- 記事IDを生成
- 記事の全文HTMLを取得
- HTMLからテキストを抽出
- Markdown形式に変換
- AIエージェントが重要情報を抽出
- 構造化された形式で出力
- データを整形
- 全記事のデータを統合
- MongoDBに保存
この一連の流れにより、元のニュース記事から必要な情報だけが効率的に抽出され、次のステップであるタイトル生成や本文執筆の素材として利用できる状態になります。
ステップ3のポイントと注意事項
ステップ3を実装する際の重要なポイントをいくつか紹介します。
Loop Over Itemsの必要性
このワークフローでは、Loop Over Itemsノードを使って記事を一つずつ処理しています。これは、HTTP Requestで外部サイトにアクセスする際のレート制限を回避し、エラーが発生した場合でも他の記事の処理に影響を与えないようにするためです。
AI Agentのプロンプト設計
AI Agentノードのプロンプトは、出力の品質を左右する最も重要な要素です。具体的な指示を与えることで、一貫性のある有用な情報を抽出できます。「3文を抽出」「150語で要約」といった数値的な制約を設けることで、出力のばらつきを抑えられます。
Structured Output Parserの活用
n8nでAI自動化を行う場合、Structured Output Parserは必須のツールです。チャット型AIツールとは異なり、ワークフローでは出力形式が明確でなければ後続の処理ができません。このノードを使うことで、確実に構造化されたデータを取得できます。
MongoDBでの進捗管理
completed_stepフィールドを使って処理の進捗を記録することで、エラーが発生した場合でもどこまで処理が完了したかを把握でき、途中から再開することが可能になります。
まとめ
ステップ3「記事のリサーチと要約」は、Content Farmingワークフローの中核を担う重要なパートです。このステップでは以下の処理が行われます。
- 記事URLからの全文コンテンツ取得
- HTMLからテキストへの変換
- AIによる重要情報の抽出と要約
- 構造化されたデータ形式での出力
- MongoDBへのデータ保存
各ノードが連携して動作することで、元のニュース記事から必要な情報だけを効率的に抽出し、次のステップで使える形式に整えることができます。
このステップを理解することで、n8nでのAI自動化ワークフローの構築方法がより明確になるはずです。Split Out、Loop Over Items、AI Agent、Structured Output Parserといった重要なノードの使い方をマスターすれば、様々な自動化シナリオに応用できます。
次回は、ステップ4以降のタイトル生成や本文執筆の部分について解説する予定です。ぜひ実際に手を動かしながら、このワークフローの仕組みを体験してみてください。