n8nを活用したブログ自動生成ワークフローの**Step 1(ステップ1)**を詳しく解説します。このステップでは、毎日正午にテクノロジー系RSSフィードからAI関連記事を自動収集し、分類・保存するまでの一連の処理を行います。n8n
Step 1の全体像
Step 1は「毎日ニュースをベクトルストアに保存する」というミッションを持ち、以下の7つのノードで構成されています

- Get Articles Daily(スケジュールトリガー)
- Set Tech News RSS Feeds(RSSフィード設定)
- Split Out(配列分割)
- Read RSS News Feeds(RSSフィード読み込み)
- Filter(日付フィルター)
- Set and Normalize Fields(フィールド正規化)
- Text Classifier(AI分類器)
それでは、各ノードを順番に見ていきましょう。
1. Get Articles Daily:毎日正午に自動実行
ノードタイプ: Schedule Trigger(スケジュールトリガー)n8n
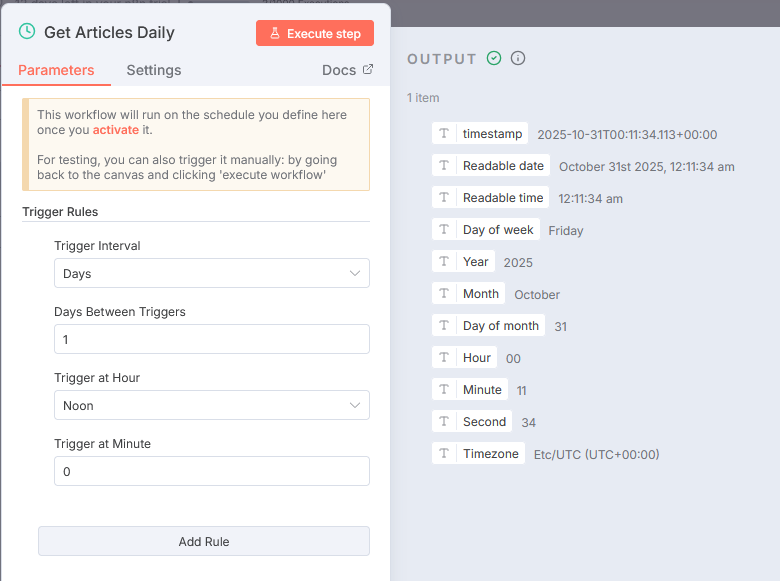
このノードがワークフロー全体のスタート地点です。設定内容は:
- 実行間隔: 1日ごと
- 実行時刻: 正午(12:00)
- 動作: 毎日正午になると自動的にワークフローを起動
スケジュールトリガーは、手動実行ではなく定期的に自動でワークフローを動かすための重要なノードです。この設定により、毎日決まった時間に最新のAIニュースを自動収集できます。n8n
2. Set Tech News RSS Feeds:監視するRSSフィードリスト
ノードタイプ: Set(データ設定)n8n
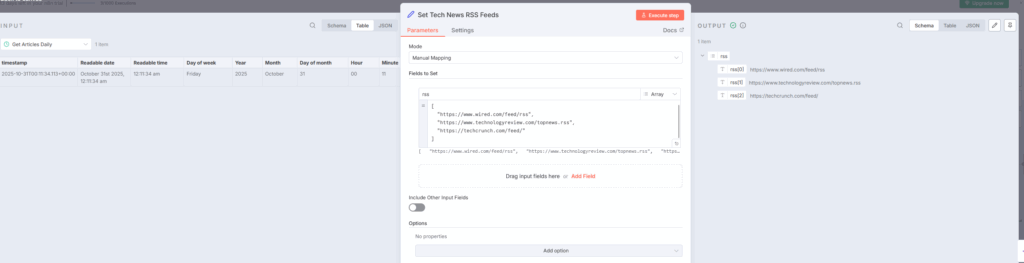
このノードでは、監視対象となる7つのテクノロジー系RSSフィードをリスト形式で定義しています(実例画像は3つのRSSのみ)
- BBC News Technology
- WIRED
- MIT Technology Review
- TechCrunch
- MarkTechPost
- HackerNoon
- Artificial Intelligence News
これらのフィードは「rss」という配列(Array)型のフィールドに格納されます。Setノードは、ワークフローで使用するデータを準備・正規化する役割を担います。indiantinker.bearblog+1
3. Split Out:配列を個別アイテムに分割
ノードタイプ: Split Out(配列分割)n8n

前のノードで設定した7つのRSSフィードURLを、個別のアイテムとして処理できるように分割します。(実例画像は3つのRSSのみ)n8n
- 分割対象フィールド:
rss - 動作: 1つの配列を7つの個別アイテムに変換
Split Outノードは、配列データを1つずつ処理するために不可欠です。このノードがないと、7つのフィードを一度に処理しようとしてエラーが発生する可能性があります。n8n
4. Read RSS News Feeds:各フィードから記事を取得
ノードタイプ: RSS Feed Read(RSSフィード読み込み)n8n+1
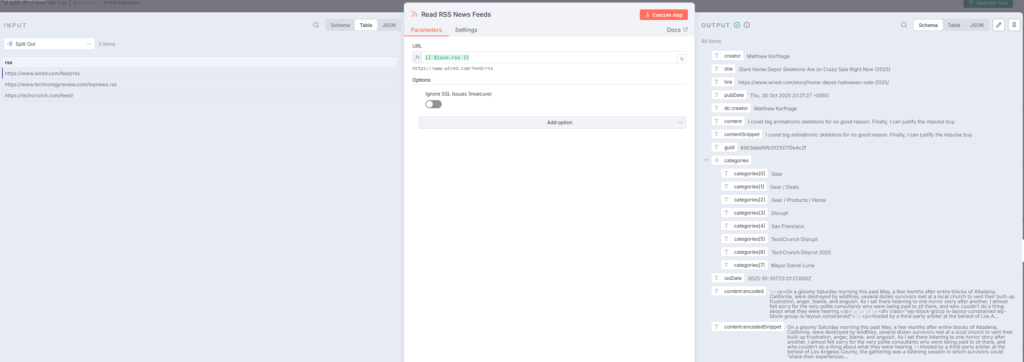
各RSSフィードから最新記事を取得します:rss
- URL:
={{ $json.rss }}(前ノードから受け取ったURL) - オプション: SSL証明書の検証を有効化
- 取得内容: タイトル、コンテンツ、日付、リンク、カテゴリーなど
このノードは各フィードを順番に読み込み、記事データを取得します。7つのフィードから合計で数十〜数百件の記事が取得されます。n8n
5. Filter:過去24時間の記事のみを抽出
ノードタイプ: Filter(条件フィルター)n8n+1
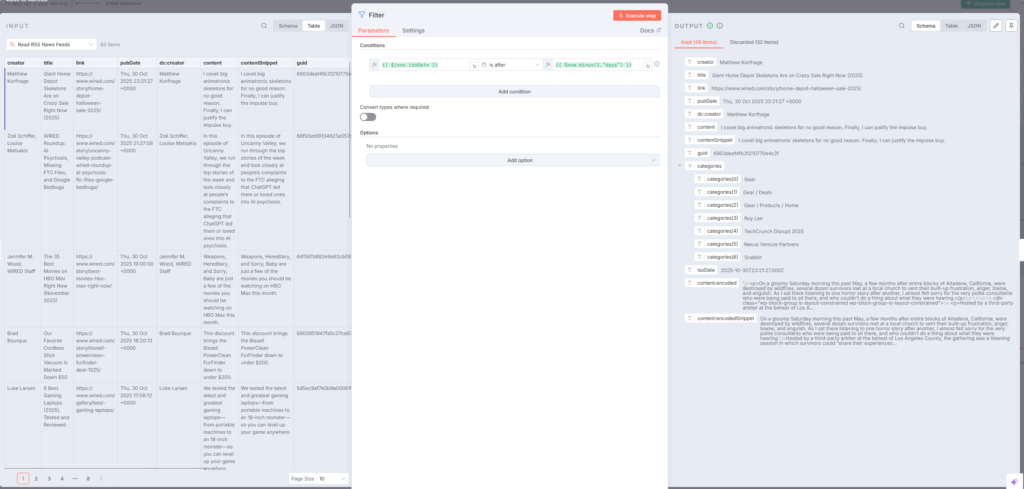
大量の記事データから、過去24時間以内に公開された記事のみを抽出します:n8n
- 条件:
{{ $json.isoDate }} is after {{ $now.minus(1, "days") }} - 動作: 現在時刻から1日前以降の記事のみを通過させる
Filterノードは条件に合致しないデータを除外し、必要なデータだけを次のノードに渡します。これにより、古い記事を処理する無駄を省けます。n8n
6. Set and Normalize Fields:データを統一フォーマットに整形
ノードタイプ: Set(フィールド正規化)n8n+1
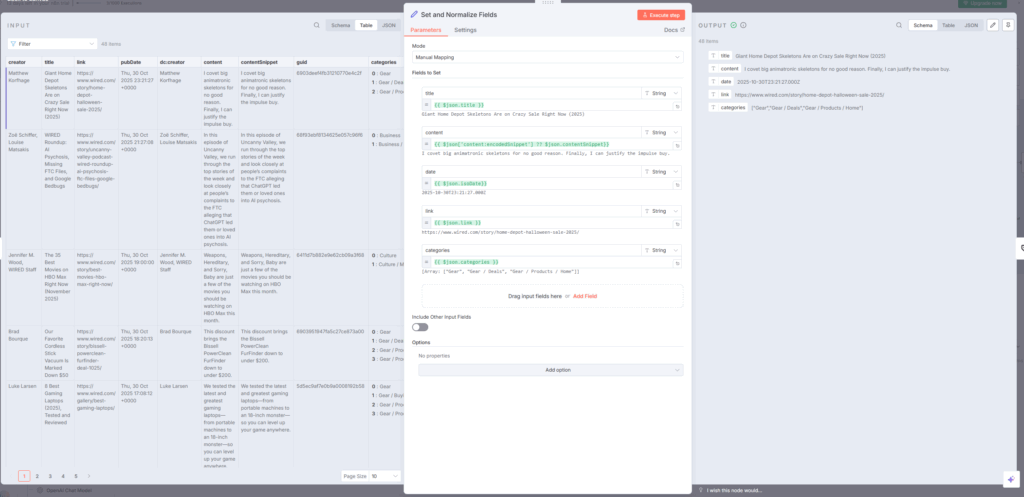
RSSフィードごとに異なるフィールド名やデータ構造を、統一されたフォーマットに変換します:indiantinker.bearblog+1
json{
"title": "{{ $json.title }}",
"content": "{{ $json['content:encodedSnippet'] ?? $json.contentSnippet }}",
"date": "{{ $json.isoDate }}",
"link": "{{ $json.link }}",
"categories": "{{ $json.categories }}"
}
ポイント:n8n+1
- フィールド名の統一: 異なるフィード間で一貫性を確保
- データ型の整合: MongoDBが期待する型に変換
- デフォルト値の設定: 存在しない場合の代替値を指定
この正規化プロセスは、後続のAI分類やデータベース保存で問題が起きないようにするための重要なステップです。indiantinker.bearblog
7. Text Classifier:AI関連記事のみを自動分類
ノードタイプ: Text Classifier(テキスト分類器)n8n+1

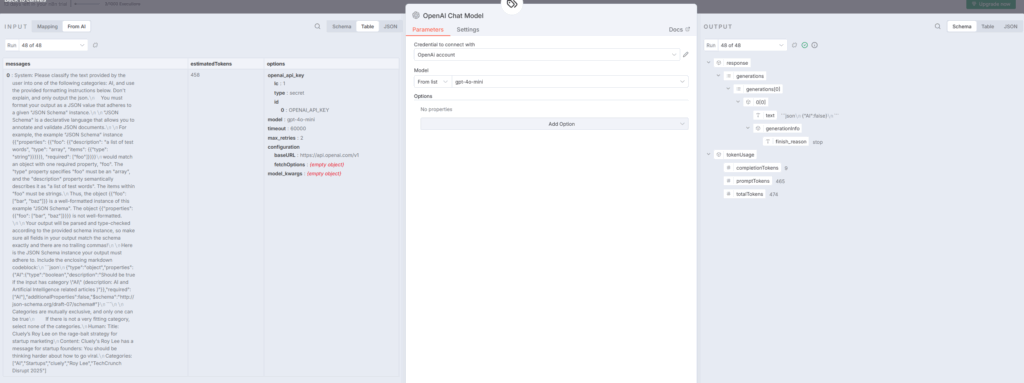
OpenAIのgpt-4o-miniモデルを使用して、記事がAI関連かどうかを自動判定します:n8n+1
分類条件:
- 入力プロンプト:
Title: {{ $json.title }}\nContent: {{ $json.content }}\nCategories: {{ $json.categories }} - カテゴリー: 「AI」(AI・人工知能関連記事)
- 不一致時の処理: 該当しない記事は破棄(discard)
Text Classifierは、大量の記事から特定のカテゴリーに属するものだけを抽出する強力なツールです。これにより、AI関連のトレンドニュースのみを次のステップに渡せます。reddit+2
まとめ:Step 1の役割と重要性
Step 1は、ブログ自動生成ワークフロー全体の基盤となる「データ収集・前処理」パイプラインです。毎日正午に自動実行され、以下の処理を行います:n8n
- 自動収集: 7つの主要テクノロジーメディアから最新記事を取得
- 時間フィルター: 過去24時間の記事のみを抽出
- データ正規化: 異なるフィード構造を統一フォーマットに変換
- AI分類: OpenAIを使ってAI関連記事のみを自動判定
このステップがあることで、人間が手動でニュースサイトを巡回する必要がなくなり、常に最新のAIトレンドを自動キャッチできるようになります。また、正規化されたデータ構造により、Step 2以降のAI解析やブログ記事生成がスムーズに進行します。n8n+1
次回: Step 2では、MongoDBに保存し、後続ステップで再利用可能にするプロセスを解説します。