n8nとAIを組み合わせたブログ自動化に興味はありませんか?前回はRSSフィード収集からリサーチまでの流れを解説しましたが、今回は最も重要な「記事生成」フェーズであるステップ4〜7に焦点を当てます。AIエージェントとMongoDBを駆使して、SEO最適化された高品質な記事を自動生成する仕組みを、ワークフローの各ブロックごとに詳しく解説します。
目次
- ステップ4〜7の全体像
- ステップ4:バイラル性の高いブログタイトル生成
- ステップ5:SEO最適化された記事アウトライン作成
- ステップ6:300〜500語/セクションの本文執筆
- ステップ7:検索エンジン向けメタデータ生成
- MongoDBでの進捗管理の仕組み
- 実装時の注意点とトラブルシューティング
- まとめ
ステップ4〜7の全体像
前回のステップ1〜3では、RSSフィードからAI関連記事を収集し、重要な情報を抽出しました。ステップ4からは、その情報をもとに実際のブログ記事を生成していきます。fn8n
このフェーズの特徴は、複数のAIエージェントが段階的に記事を磨き上げていく点です。各ステップでMongoDBに進捗状況(completed_step)を保存することで、エラーが発生しても中断した場所から再開できる堅牢な設計になっています。
全体のフローは以下の通りです。
ステップ4:ブログタイトル生成 → MongoDB3 → AI Agent2 → AI Agent3 → Code7 → MongoDB7
ステップ5:記事アウトライン作成 → MongoDB7 → AI Agent5 → Code3 → MongoDB4
ステップ6:本文執筆 → MongoDB4 → AI Agent6 → Code5 → MongoDB5
ステップ7:SEOメタデータ生成 → MongoDB5 → AI Agent7 → Code6 → MongoDB6
各ステップでは、AIエージェントがGPT-4o-miniモデルを使用して高品質なコンテンツを生成し、Codeノードでデータを整形してからMongoDBに保存します。n8n+1
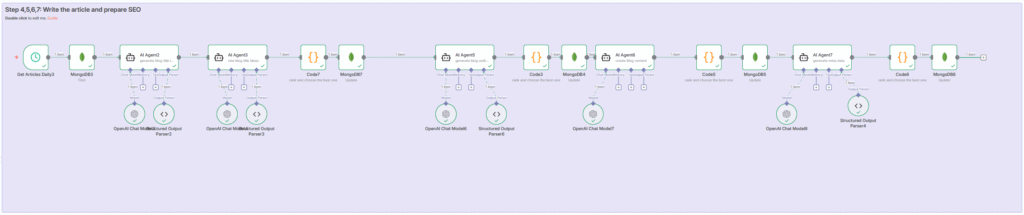
ステップ4:バイラル性の高いブログタイトル生成
ステップ4では、読者の好奇心を引くタイトルを生成します。このステップは5つのブロックで構成されています。
MongoDB3:記事データの取得
最初のブロックはMongoDB3ノードです。このノードはcompleted_stepが3の記事、つまりステップ3でリサーチが完了した記事を1件取得します。indiantinker.bearblog
- Operation: find
- Collection: blog
- Query:
{"completed_step":3} - Options:
{"limit": 1}
この設定により、まだタイトル生成が行われていない記事のみが処理対象となります。

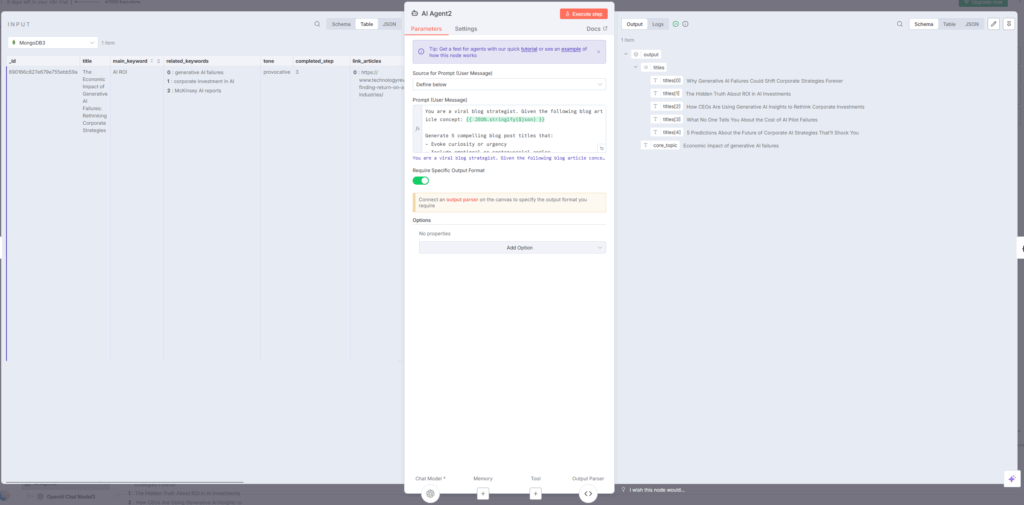
AI Agent2:5つのタイトル候補を生成
次にAI Agent2ノードが、前のステップで収集した記事情報をもとに5つのタイトル候補を生成します。このエージェントには「バイラルブログストラテジスト」という役割が与えられています。
プロンプトの重要なポイント:
- 好奇心や緊急性を喚起する
- 感情的または論争的な角度を含める
- ロングテールキーワードでSEO対策
- 明確で具体的、クリックしたくなる内容
タイトルフォーマットの例:
- 「なぜ[X]は[Y]のすべてを変えようとしているのか」
- 「[トピック]について誰も教えてくれない隠された真実」
- 「[ペルソナ]が[X]を使って[Y]する方法」
AI Agent2は構造化出力パーサーと連携し、以下の形式でJSONを返します。
json{
"titles": [
"Why AI Code Review Will Replace Junior Engineers",
"How AI is Reshaping Software QA in 2025",
...
],
"core_topic": "AI software engineers"
}

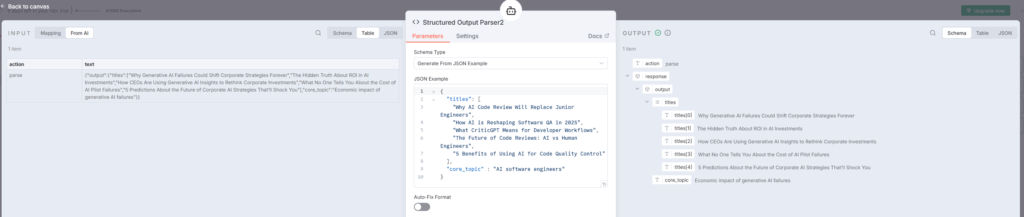
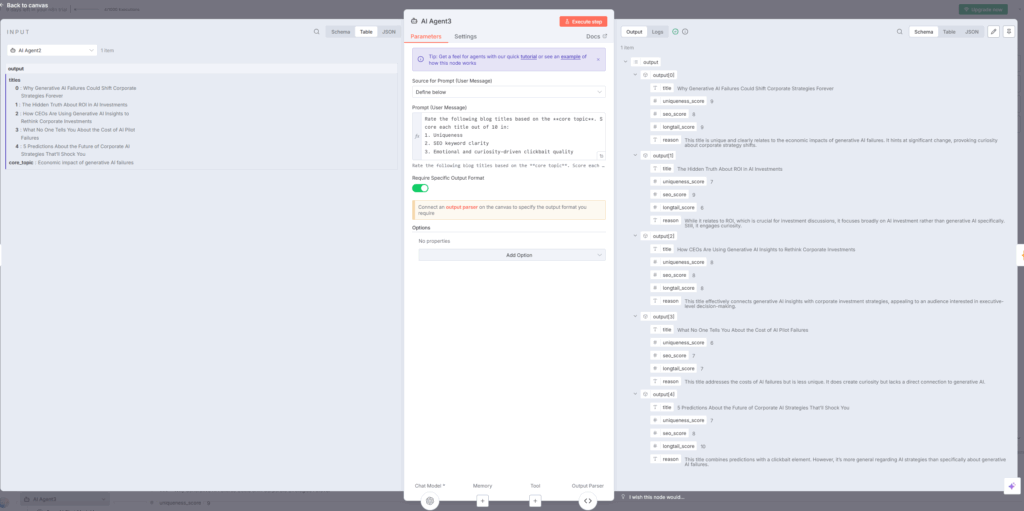
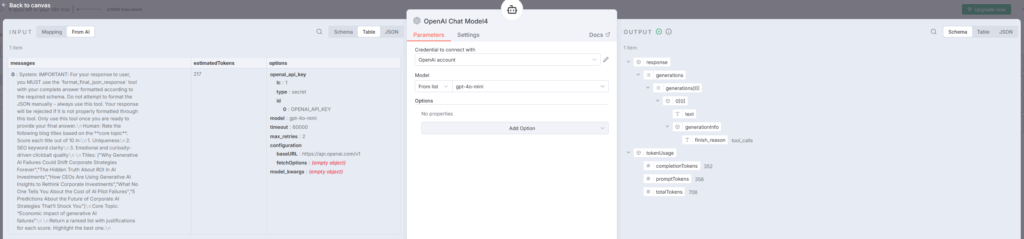
AI Agent3:各タイトルを10点満点で評価
AI Agent3ノードは、生成された5つのタイトルを3つの観点から10点満点で評価します。youtube
評価基準:
- ユニーク性(Uniqueness):他の記事との差別化
- SEOキーワードの明確さ(SEO keyword clarity):検索意図の明確性
- 感情・好奇心を引くクリックベイト品質(Emotional and curiosity-driven clickbait quality):クリック率向上
AI Agent3の出力例:
json[
{
"title": "Why AI Code Review Will Replace Junior Engineers",
"uniqueness_score": 8,
"seo_score": 7,
"longtail_score": 9,
"reason": "Strong intent signal ('why'), specific audience reference..."
},
...
]
Code7:最高スコアのタイトルを選択
Code7ノードでは、JavaScriptを使って平均スコアが最も高いタイトルを選択します。
主な処理内容:
javascript// 各タイトルの平均スコアを計算
for (const item of input) {
item.average_score = (
(item.uniqueness_score || 0) +
(item.seo_score || 0) +
(item.longtail_score || 0)
) / 3;
}
// 平均スコア降順でソート
input.sort((a, b) => b.average_score - a.average_score);
// トップタイトルを返す
return {
blog_title: input[0].title,
blog_title_ideas: input,
core_topic: ...,
completed_step: 4
}
このロジックにより、最も効果的なタイトルが自動的に選ばれます。

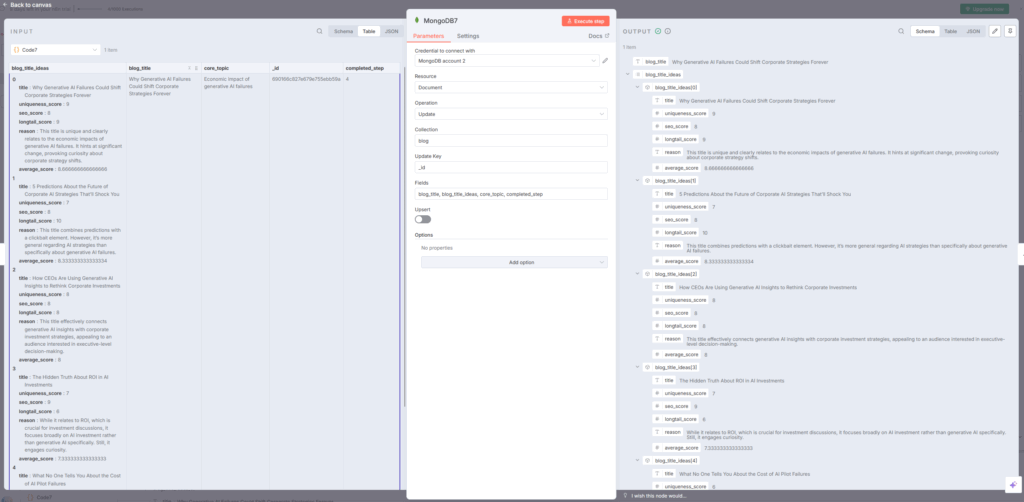
MongoDB7:選択したタイトルを保存
最後にMongoDB7ノードで、選択されたタイトルと関連データをMongoDBに保存します。indiantinker.bearblog
- Operation: update
- Update Key:
_id - Fields:
blog_title,blog_title_ideas,core_topic,completed_step
completed_stepを4に更新することで、次のステップに進む準備が整います。
ステップ5:SEO最適化された記事アウトライン作成
ステップ5では、選択されたタイトルに基づいてH1/H2構造の記事アウトラインを生成します。
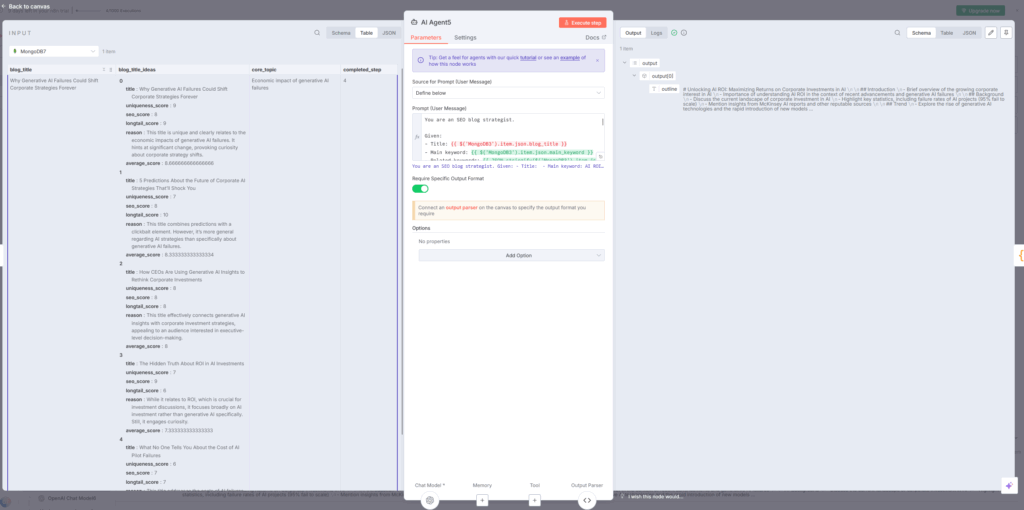
AI Agent5:SEO戦略家としてアウトライン生成
AI Agent5ノードは「SEOブログストラテジスト」として、以下の要素を含むアウトラインを生成します。note
入力データ:
- タイトル
- メインキーワード
- 関連キーワード
- 関連記事情報
アウトライン構成:
- Intro(導入):問題提起と読者の関心喚起
- Background(背景):基礎知識と文脈
- Trend(トレンド):現在の動向
- Insight(洞察):独自の分析
- Forecast(予測):将来の展望
- CTA(行動喚起):読者への次のステップ
このアウトラインはGoogleのフィーチャードスニペットに最適化されており、検索結果の上位表示を狙います。n8n
AI Agent5の出力例:
# Navigating Legal Complexities in AI and Copyright: A Complete Guide
## Introduction: The Intersection of AI and Copyright
The rise of generative AI has sparked a seismic shift...
## Background: Understanding AI and Copyright
In order to grasp the complexities...
## Trend: The Rise of Generative AI and Its Impact
The increasing sophistication...
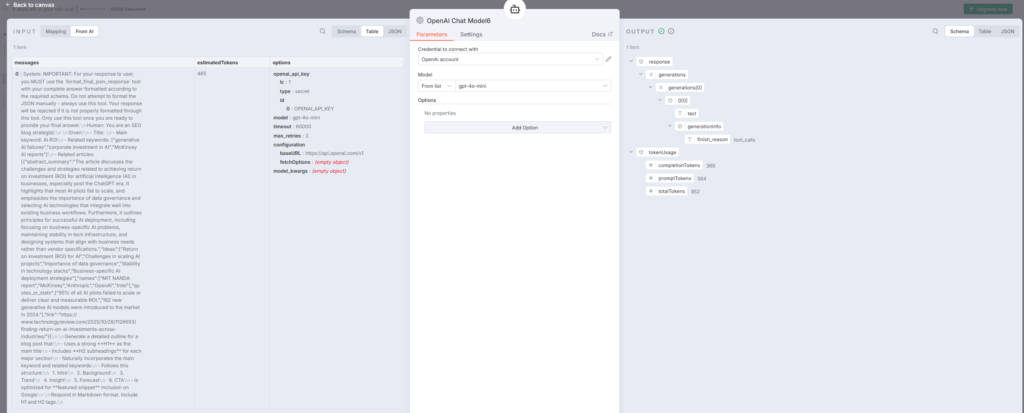
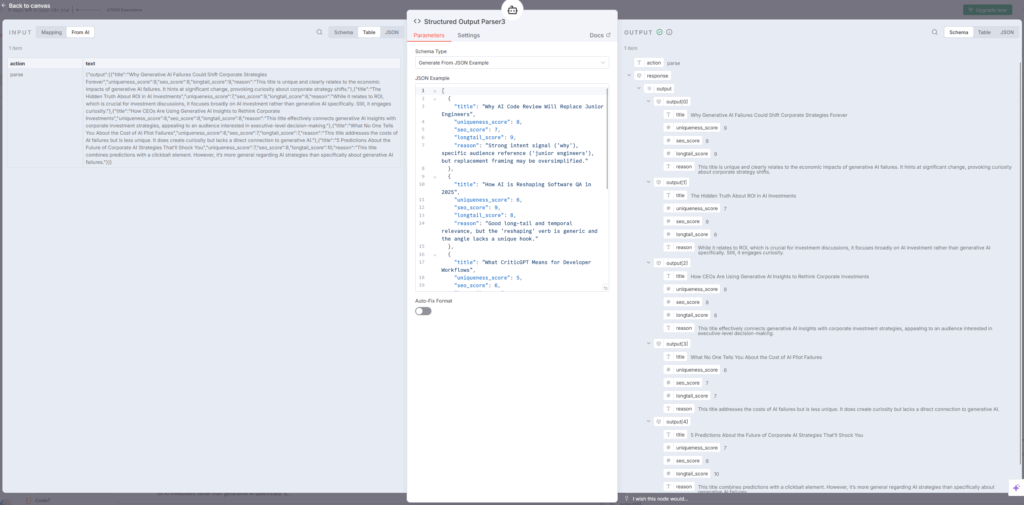
Code3:マークダウンフェンスの削除と文字列エスケープ
Code3ノードでは、AI Agent5が生成したアウトラインを整形します。indiantinker.bearblog
処理内容:
javascript// マークダウンフェンス (```
outline = outline
.replace(/```markdown\n?/g, '')
.replace(/```
.trim();
// バックスラッシュとダブルクォートをエスケープ
outline = outline
.replace(/\\/g, '\\\\')
.replace(/"/g, '\\"');
この処理により、MongoDBに保存する際の文字列エラーを防ぎます。

MongoDB4:アウトラインと進捗を保存
MongoDB4ノードで、整形されたアウトラインとcompleted_step=5を保存しますbitcot。
- Operation: update
- Fields:
blog_outline,completed_step

ステップ6:300〜500語/セクションの本文執筆
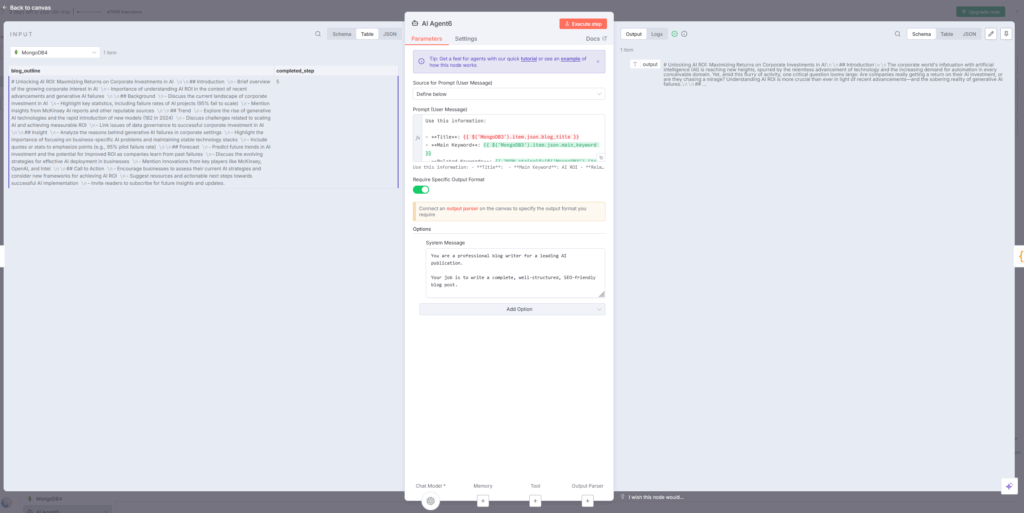
ステップ6では、アウトラインに沿って詳細な記事本文を執筆します。このステップが最も重要で、記事のクオリティを左右しますn8n。
AI Agent6:プロフェッショナルなブログライターとして執筆
AI Agent6ノードは「大手AI出版社のプロフェッショナルブログライター」という役割で記事を執筆しますn8n。
システムメッセージ:
You are a professional blog writer for a leading AI publication. Your job is to write a complete, well-structured, SEO-friendly blog post.
執筆指示の主なポイント:
- 各セクション300〜500語で執筆
- メインキーワードと関連キーワードを自然に含める
- 最低2つの引用を含める
- 1つの比喩や例で明確化
- 将来の展望や予測を含める
- 指定されたトーン(分析的、教育的、挑発的など)を維持
- マークダウン形式で記述
入力データ:
- タイトル
- メインキーワード
- 関連キーワード
- トーン
- アウトライン
- 関連記事
- 引用元URL
このプロンプトにより、単なる情報の羅列ではなく、読み応えのある質の高い記事が生成されますn8n。
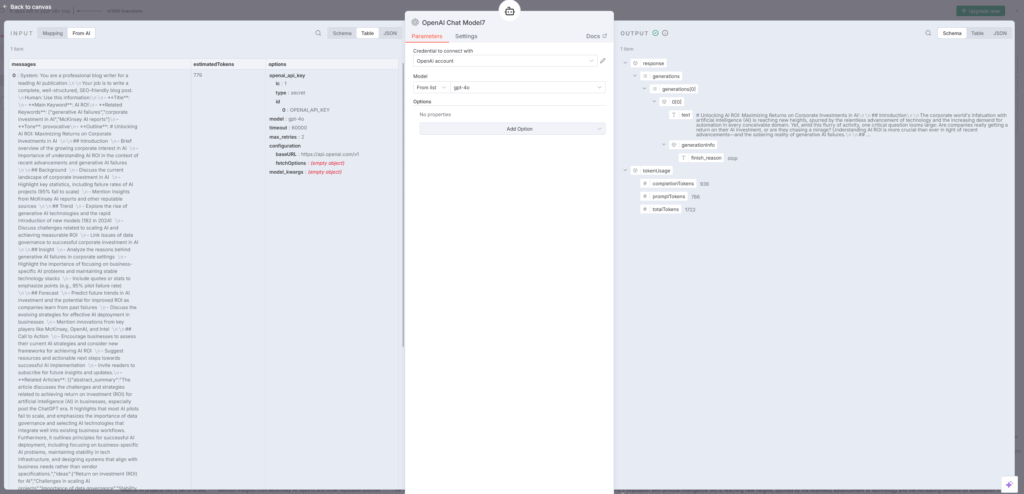
Code5:本文のフォーマット整形
Code5ノードでは、AI Agent6が生成した本文を整形します。Code3と同様に、マークダウンフェンスの削除と文字列のエスケープ処理を行いますbitcot。
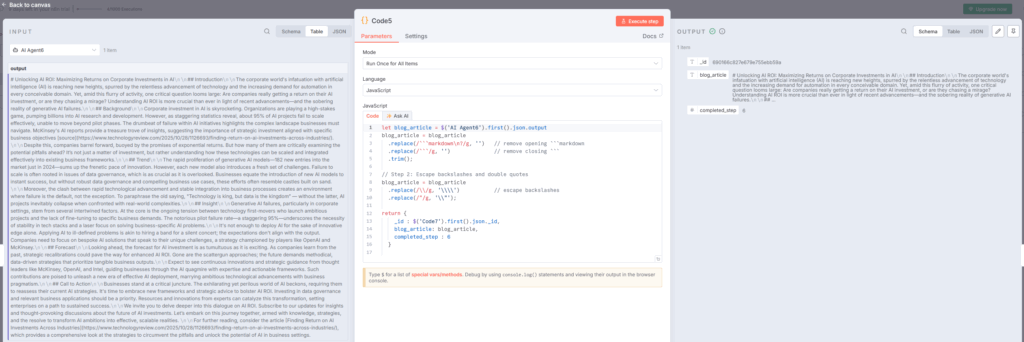
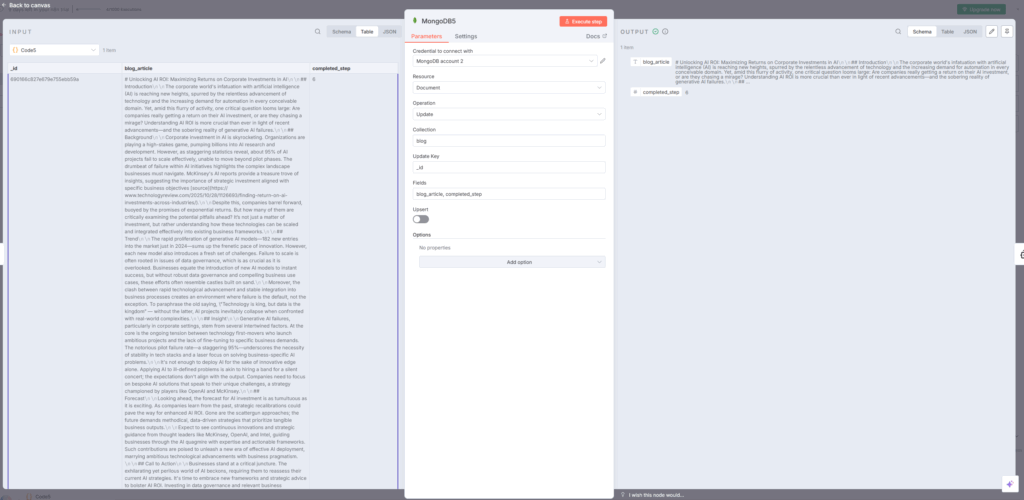
MongoDB5:本文を保存
MongoDB5ノードで、完成した記事本文とcompleted_step=6を保存しますbitcot。
- Operation: update
- Fields:
blog_article,completed_step
ステップ7:検索エンジン向けメタデータ生成
最終ステップであるステップ7では、SEOに必要なメタデータを生成しますn8n。
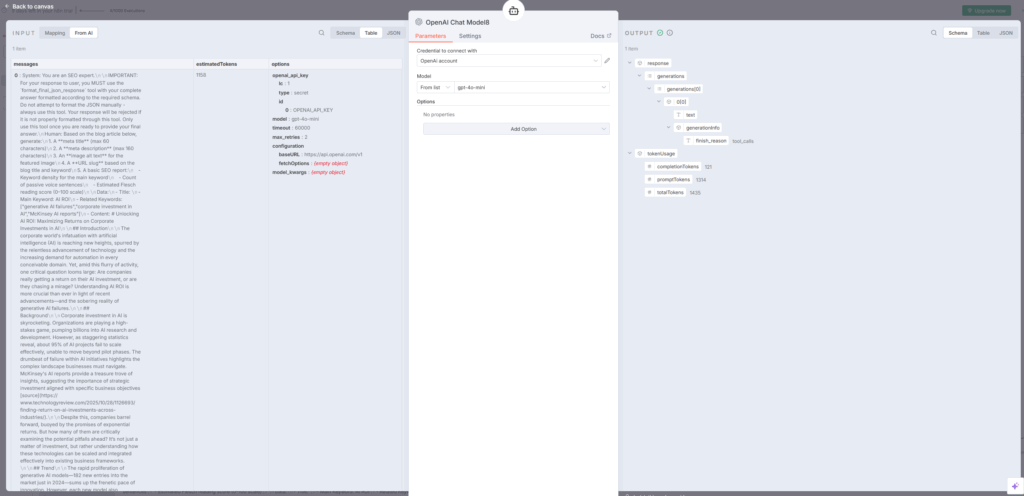
AI Agent7:SEOエキスパートとしてメタデータ生成
AI Agent7ノードは「SEOエキスパート」として、以下の項目を生成しますn8n。
生成項目:
- メタタイトル(最大60文字):検索結果に表示されるタイトル
- メタディスクリプション(最大160文字):検索結果の説明文
- 画像alt属性:アイキャッチ画像の説明
- URLスラグ:SEOフレンドリーなURL
- SEOレポート:
- キーワード密度
- 受動態文の数
- Flesch読みやすさスコア(0〜100)
システムメッセージ:
You are an SEO expert.
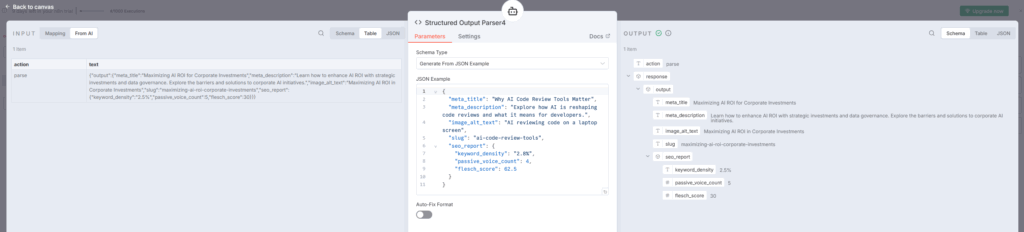
出力例:
{
"meta_title": "Why AI Code Review Tools Matter",
"meta_description": "Explore how AI is reshaping code reviews...",
"image_alt_text": "AI reviewing code on a laptop screen",
"slug": "ai-code-review-tools",
"seo_report": {
"keyword_density": "2.8%",
"passive_voice_count": 4,
"flesch_score": 62.5
}
}

Code6:メタデータの整形
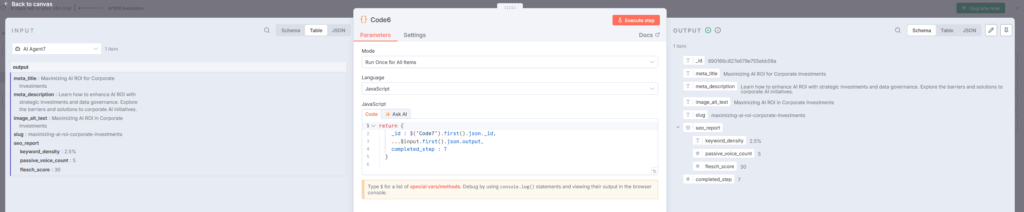
Code6ノードでは、AI Agent7の出力をそのままMongoDBに保存できる形式に整形しますbitcot。
return {
_id: $('Code7').first().json._id,
...$input.first().json.output,
completed_step: 7
}
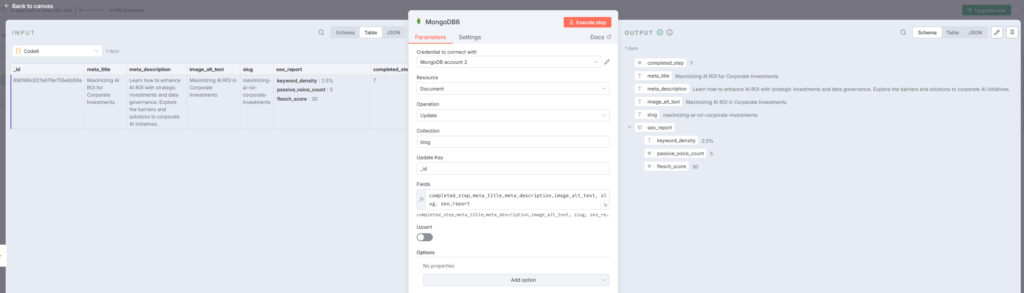
MongoDB6:メタデータを保存
MongoDB6ノードで、すべてのメタデータとcompleted_step=7を保存しますbitcot。
保存フィールド:
completed_stepmeta_titlemeta_descriptionimage_alt_textslugseo_report
これでステップ7が完了し、記事生成フェーズが終わります。次のステップ8では画像生成、ステップ9ではWordPress投稿へと進みますn8n。
MongoDBでの進捗管理の仕組み
このワークフローの優れた点は、MongoDBを使った堅牢な進捗管理にありますbitcot。
completed_stepフィールドの役割
各ステップの最後でcompleted_stepフィールドを更新することで、記事がどの段階まで処理されたかを追跡できます。
進捗状態:
completed_step: 3– リサーチ完了completed_step: 4– タイトル生成完了completed_step: 5– アウトライン作成完了completed_step: 6– 本文執筆完了completed_step: 7– メタデータ生成完了
エラーからの回復
万が一、ステップ5でエラーが発生した場合でも、次回の実行時にはcompleted_step=4の記事を取得して処理を再開できますbitcot。これにより、同じ記事を何度も処理する無駄を防ぎ、API利用料を節約できます。
クエリによる効率的な処理
各MongoDBノードは、前のステップが完了した記事のみを取得するため、処理の重複がありませんbitcot。
例:
- MongoDB3:
{"completed_step":3}を検索 - MongoDB7:
{"completed_step":4}を検索(次回実行時)
実装時の注意点とトラブルシューティング
実際にこのワークフローを実装する際の重要なポイントをまとめます。
文字列エスケープの重要性
Codeノードでバックスラッシュとダブルクォートをエスケープする処理は、MongoDB保存時のエラーを防ぐために必須ですbitcot。AIが生成するマークダウン形式の文章には、これらの文字が頻繁に含まれるため、適切な処理が必要です。
OpenAI APIのレート制限
GPT-4o-miniを使用しているため、1日10記事であれば月額約6ドルで運用できますn8n。ただし、大量の記事を一度に処理する場合は、OpenAIのレート制限に注意が必要ですyoutube。
プロンプトのカスタマイズ
各AI Agentのプロンプトは、あなたのブログのトーンやスタイルに合わせてカスタマイズできますnote+1。特に以下の要素は調整を推奨します:
- タイトルのフォーマット
- アウトラインの構成
- 記事の長さ(現在は300〜500語/セクション)
- トーン(分析的、教育的、挑発的など)
MongoDB接続の確認
ワークフロー実行前に、MongoDB Atlasの接続設定が正しいか確認しましょうn8n。接続文字列のパスワードとデータベース名が正しく置き換えられているかをチェックしてください。
構造化出力パーサーの安定性
Structured Output Parserノードは、AIの出力をJSON形式に変換します[。稀にAIが指定形式と異なる出力をする場合があるため、エラーハンドリングを追加することを検討してください。
まとめ
ステップ4〜7では、複数のAIエージェントが連携して高品質なSEO記事を自動生成します。各ステップのポイントをまとめると:
- ステップ4では、バイラル性の高いタイトルを5つ生成し、3つの観点から評価して最適なものを選択する
- ステップ5では、SEO最適化されたH1/H2構造のアウトラインを作成し、Googleフィーチャードスニペットを狙う
- ステップ6では、プロフェッショナルなライターとして300〜500語/セクションで詳細な本文を執筆する
- ステップ7では、メタタイトル、メタディスクリプション、URLスラグなどSEOに必要な要素を生成する
- MongoDBの
completed_stepフィールドで進捗を管理し、エラーからの回復を可能にする
このワークフローを導入すれば、1日10記事を月額約21ドルで自動生成できますn8n。AIブログ運営や独立を考えている方は、ぜひこのシステムを活用してコンテンツ制作の効率化を図ってください。
次回は、ステップ8の画像生成とステップ9のWordPress投稿について解説する予定です。